
文本
如何使用Selenium Automation测试PDF文件?
PDF文档是小型,高度安全的文件。几乎所有企业都使用PDF来处理其文件。原因是无论使用哪种工具访问PDF文件,都保持格式的显着特征。 毫不奇怪,我们的所有发票,正式文件,合同文件,登机牌,银行对帐单等通常都是PDF格式。
即使是开发人员,我们也会遇到需要验证PDF文件或将其用于定位数据某些部分的情况。考虑到您有足够的时间来闲暇,您可以手动执行此操作,也可以选择自动化测试。在使用自动化处理此类文件的棘手组件时,似乎有点棘手。但是事实并非如此。selenium测试自动化可以非常轻松地测试PDF文件格式。
在此博客文章中,我们将探讨selenium测试PDF文件的棘手主题,并提出不同的解决方案来使用自动化处理PDF文档。
为什么测试PDF文件很重要?
在当今世界中,PDF文件格式通常用于生成正式信件,文档,合同和其他重要文件。主要是因为不能编辑PDF,而可以编辑Word格式。因此,以PDF格式存储机密信息被认为是一种良好的安全措施。
这种高度安全的文档必须始终包含准确的细节,必须确保提供的信息是经过验证的。PDF文档需要以一种人类可读而不是机器可读的方式生成。手动验证和验证文档很容易,但它带来了与时间相关的重大挑战。
当验证必须自动化时会发生什么?
这是自动化测试人员面临的一个复杂问题,这也是Selenium测试PDF文件出现的原因。让我给你一个实际的例子,测试PDF文档成为基本的设计要求。
在银行系统中,当我们需要特定时期的对帐单时,该对帐单将以PDF格式下载。该文件将包含用户的基本信息以及规定期间内的交易。
如果这种设计在投入使用前没有得到高准确性的验证,最终用户将面临他们的帐户报表中的多重差异。因此,负责测试这一要求的人员必须确保报表中打印的所有细节与客户执行的信息或行动完全匹配。
我希望这可以证明Selenium测试PDF文件的机智。让我们通过向您展示可以使用Selenium进行PDF测试执行的不同操作来开始本Selenium测试PDF文件教程。
为什么Selenium自动化测试对您的下一个版本至关重要?
如何在Selenium Webdriver中处理PDF?
要在Selenium测试自动化中处理PDF文档,我们可以使用一个名为PDFBox的java库。Apache PDFBox是一个专门帮助处理PDF文档的开源库。我们可以使用它来验证文档中的文本,提取文档中的文本或图像的特定部分,等等。要在Selenium测试PDF文件中使用它,我们需要在pom.xml文件中添加maven依赖项,或者将其作为外部jar添加。
要添加为Maven依赖项,请执行以下操作:
导航到以下URL https://mvnrepository.com/artifact/org.apache.pdfbox
选择最新版本并将其放在pom.xml文件中。Maven的依赖关系如下
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.20</version>
</dependency>
要添加为外部jar:
在以下路径中下载jar文件 https://repo1.maven.org/maven2/org/apache/pdfbox/pdfbox/2.0.20/
转到您的项目,选择configure Build Path并添加外部jar文件,如下所示。
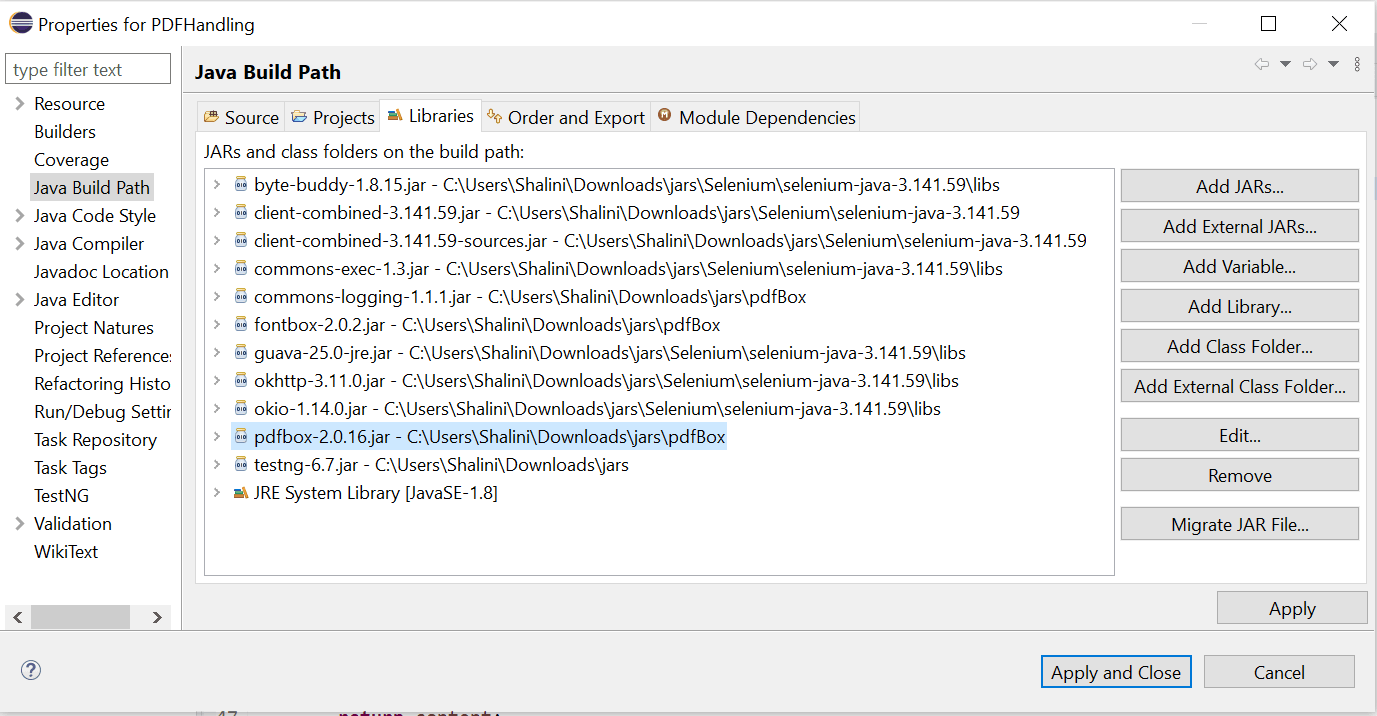
处理selenium中的pdf 在项目中添加依赖项或jar之后,最好使用编码部分。
验证PDF中的内容
在关于Selenium测试PDF文件的本教程的下一步,我们将找到如何验证PDF内容的方法。 要检查PDF文档中是否存在特定文本,我们使用PDFTextStripper,可以从org.apache.pdfbox.util.PDFTextStripper导入。
这是我们可以使用Selenium进行PDF测试并验证其内容的代码。
package Automation;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.testng.Assert;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
public class PdfHandling {
WebDriver driver = null;
@BeforeTest
public void setUp() {
//specify the location of the driver
System.setProperty("webdriver.chrome.driver", "C:\\Users\\Shalini\\Downloads\\Driver\\chromedriver.exe");
//instantiate the driver
driver = new ChromeDriver();
}
@Test
public void verifyContentInPDf() {
//specify the url of the pdf file
String url ="http://www.pdf995.com/samples/pdf.pdf";
driver.get(url);
try {
String pdfContent = readPdfContent(url);
Assert.assertTrue(pdfContent.contains("The Pdf995 Suite offers the following features"));
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@AfterTest
public void tearDown() {
driver.quit();
}
public static String readPdfContent(String url) throws IOException {
URL pdfUrl = new URL(url);
InputStream in = pdfUrl.openStream();
BufferedInputStream bf = new BufferedInputStream(in);
PDDocument doc = PDDocument.load(bf);
int numberOfPages = getPageCount(doc);
System.out.println("The total number of pages "+numberOfPages);
String content = new PDFTextStripper().getText(doc);
doc.close();
return content;
}
public static int getPageCount(PDDocument doc) {
//get the total number of pages in the pdf document
int pageCount = doc.getNumberOfPages();
return pageCount;
}
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="PDF Handling">
<test name="Verify Pdf content">
<classes>
<class name="Automation.PdfHandling"/>
</classes>
</test>
</suite>
要运行测试,请单击类-> Run As-> TestNG Test。
输出控制台将显示指示成功和失败案例的默认测试报告。
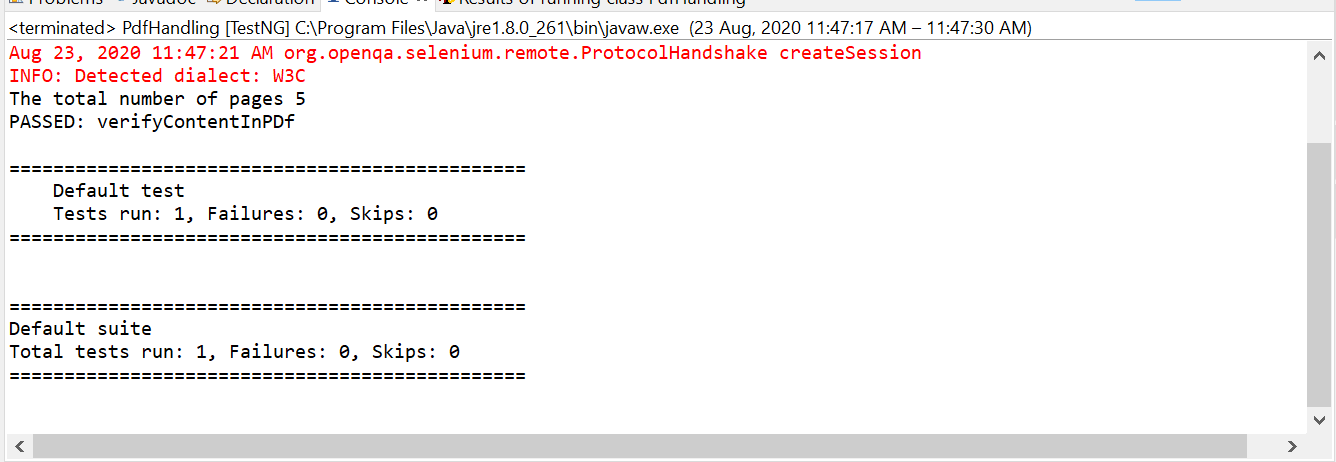
TestNG console
下载文件
有时在开始使用Selenium测试PDF文件之前,我们需要下载它们。要从网页下载PDF文件,我们需要指定定位器来识别下载链接。我们还需要禁用弹出窗口,该窗口要求我们指定路径,其中下载的文件必须放置。
在开始Selenium测试PDF文件之前,可以使用这段代码下载PDF文件。
package Automation;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
public class DownloadPdf {
WebDriver driver = null;
@BeforeTest
public void setUp() {
System.setProperty("webdriver.chrome.driver", "C:\\Users\\Shalini\\Downloads\\Driver\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
Map<String, Object> prefs = new HashMap<String, Object>();
prefs.put("download.prompt_for_download", false);
options.setExperimentalOption("prefs", prefs);
driver = new ChromeDriver(options);
}
@Test
public void downloadPdf() {
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
driver.manage().window().maximize();
driver.get("https://www.learningcontainer.com/sample-pdf-files-for-testing");
//locator to click the pdf download link
driver.findElement(By.xpath("//*[@id=\"bfd-single-download-810\"]/div/div[2]/a/p[1]/strong")).click();
}
@AfterTest
public void tearDown() {
driver.quit();
}
}
Console output
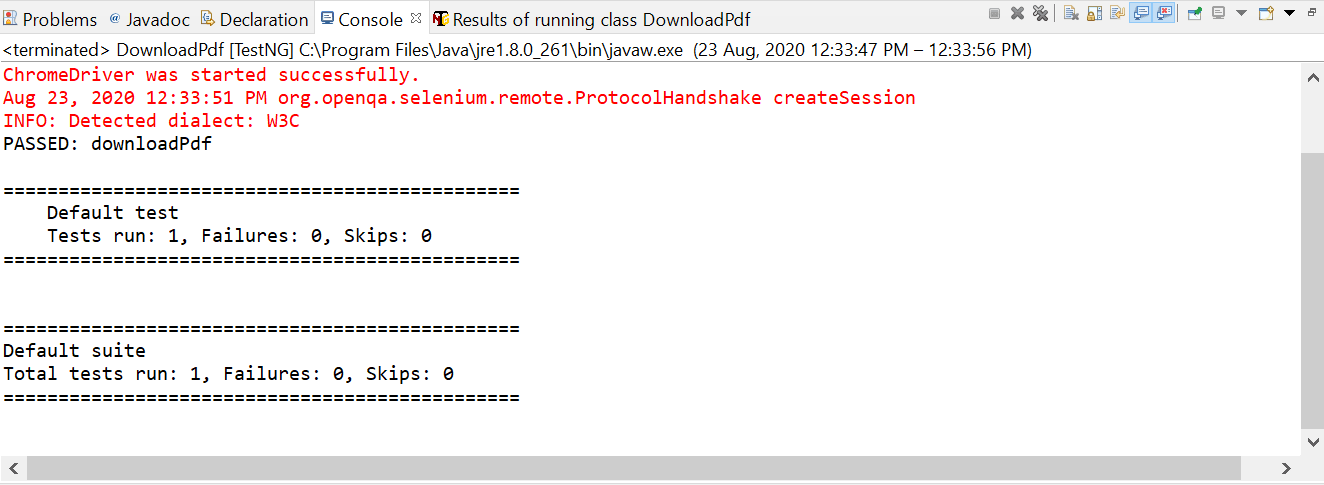
TestNG output console

设置PDF文档的开头
使用Selenium测试PDF文件,验证一个小的PDF文件将是一项简单的任务。但是对于更大的文件,你会怎么做呢?解决办法很简单。您可以设置PDF的起始页,并使用Selenium继续对PDF测试进行验证。
如果你看一下我在这篇文章中提到的PDF链接示例,它包含5页,引言从第2页开始。如果startpage在代码中设置为2,并且打印了文本,您可以看到从第二个页面打印的内容。如前所述,如果文件大小很大,您可以设置文档的开始、提取内容并验证内容。
下面是为Selenium测试PDF文件设置文档开头的简单代码。
package Automation;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.testng.Assert;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
public class ExtractContent {
WebDriver driver = null;
@BeforeTest
public void setUp() {
//specify the location of the driver
System.setProperty("webdriver.chrome.driver", "C:\\Users\\Shalini\\Downloads\\Driver\\chromedriver.exe");
//instantiate the driver
driver = new ChromeDriver();
}
@Test
public void verifyContentInPDf() {
//specify the url of the pdf file
String url ="http://www.pdf995.com/samples/pdf.pdf";
driver.get(url);
try {
String pdfContent = readPdfContent(url);
System.out.println(pdfContent);
Assert.assertTrue(pdfContent.contains("Introduction"));
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@AfterTest
public void tearDown() {
driver.quit();
}
public static String readPdfContent(String url) throws IOException {
URL pdfUrl = new URL(url);
InputStream in = pdfUrl.openStream();
BufferedInputStream bf = new BufferedInputStream(in);
PDDocument doc = PDDocument.load(bf);
PDFTextStripper pdfStrip = new PDFTextStripper();
pdfStrip.setStartPage(2);
String content = pdfStrip.getText(doc);
doc.close();
return content;
}
public static int getPageCount(PDDocument doc) {
//get the total number of pages in the pdf document
int pageCount = doc.getNumberOfPages();
return pageCount;
}
}
view raw
控制台显示从第二个页面开始的内容。

正如我们在本教程前面讨论过的Selenium测试PDF文件—当文件大小很大时,您可以设置文档的起始页,提取内容并继续进行验证。
但是,如果必须打印特定页面的整个内容呢?
如果我们只设置开始页并打印内容,那么从指定页开始的所有内容都将打印到文档的末尾。如果文件大小过大,这不是一个好的选择。相反,我们也可以设置文档的结束页!
这难道不会使Selenium测试PDF文件更容易吗?
如果我们希望打印从第2页到第3页的内容,我们可以在代码中设置以下选项。
pdfStrip.setStartPage(2);
pdfStrip.setEndPage(3);
如果我们想打印一个页面的全部内容,我们可以在开始页和结束页提到相同的页码。
pdfStrip.setStartPage(2);
pdfStrip.setEndPage(2);
在这个Selenium测试PDF文件教程的下一节中,我们将研究在基于云的平台上使用Selenium Grid进行PDF测试。
使用Selenium LambdaTest网格进行PDF测试
上面使用Selenium执行的所有PDF测试操作也可以在在线Selenium网格上执行。LambdaTest网格为在云中自动化测试提供了一个很好的选项。我们可以在多个环境或浏览器中执行测试,这有助于我们确定web页面的行为。
使用LambdaTest,您可以在2000多个浏览器、设备和操作系统上执行Selenium测试PDF文件。现在,在这个Selenium测试PDF文件教程中,我们将看到如何实现在LambdaTest网格中处理的相同的PDF操作。
要在LambdaTest网格中对PDF文件进行Selenium测试,我们需要创建一个帐户。你可以在这里免费注册。
一旦登录,您将被提供一个用户名和一个访问键,可以通过点击下面突出显示的键图标来查看。
必须在下面的代码中替换用户名和访问密钥。
package Automation;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.Assert;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
public class PdfHandlingInGrid {
String username = "Your username"; //Enter your username
String accesskey = "Your access Key"; //Enter your accesskey
static RemoteWebDriver driver = null;
String gridURL = "@hub.lambdatest.com/wd/hub";
boolean status = false;
@BeforeTest
public void setUp()throws MalformedURLException
{
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("browserName", "chrome"); //To specify the browser
capabilities.setCapability("version", "70.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", "PdfTestLambdaTest"); //To identify the test
capabilities.setCapability("name", "PDFHandling");
capabilities.setCapability("network", true); //To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
@Test
public void pdfHandle() {
String url ="http://www.pdf995.com/samples/pdf.pdf";
driver.get(url);
try {
String pdfContent = readPdfContent(url);
System.out.println(pdfContent);
Assert.assertTrue(pdfContent.contains("Introduction"));
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@AfterTest
public void tearDown() {
driver.quit();
}
public static String readPdfContent(String url) throws IOException {
URL pdfUrl = new URL(url);
InputStream in = pdfUrl.openStream();
BufferedInputStream bf = new BufferedInputStream(in);
PDDocument doc = PDDocument.load(bf);
PDFTextStripper pdfStrip = new PDFTextStripper();
pdfStrip.setStartPage(2);
pdfStrip.setEndPage(2);
String content = pdfStrip.getText(doc);
doc.close();
return content;
}
public static int getPageCount(PDDocument doc) {
int pageCount = doc.getNumberOfPages();
return pageCount;
}
}
TestNG.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="PDF Handling">
<test name="Verify Pdf content">
<classes>
<class name="Automation.PdfHandlingInGrid"/>
</classes>
</test>
</suite>
控制台输出控制台输出只在第二页中显示PDF文档的内容,因为开始页和结束页都是相同的。
如何在LambdaTest仪表板中查看您的测试
Selenium测试PDF文件的下一个主要步骤是查看测试结果并验证它们。一旦您成功地执行了测试用例,导航到LambdaTest仪表板页面。此页对已运行的测试进行了简要描述。
 要获得关于每个测试的详细信息,请导航到自动化选项卡。
要获得关于每个测试的详细信息,请导航到自动化选项卡。
在LambdaTest网格中运行的测试将被放在源代码中提供的目录中。在代码中,我们将路径名设置为PdfTestLambdaTest,这将帮助我们在仪表板中定位测试。
capabilities.setCapability("build", "PdfTestLambdaTest"); //To identify the test
LambdaTest还提供各种过滤器来标识运行的测试。 可以根据执行日期,构建名称以及构建状态来过滤测试。 通过单击构建,我们将导航到详细的测试页面,其中将列出在特定构建中运行的所有测试。
将列出有关浏览器,其版本,测试状态的信息,并在网格中运行时记录测试,并且可以借助视频记录功能轻松跟踪和修复测试执行过程中的任何故障。 这将Selenium测试PDF文件提升到另一个层次。
以下是在LambdaTest网格中运行的测试结果的屏幕截图。
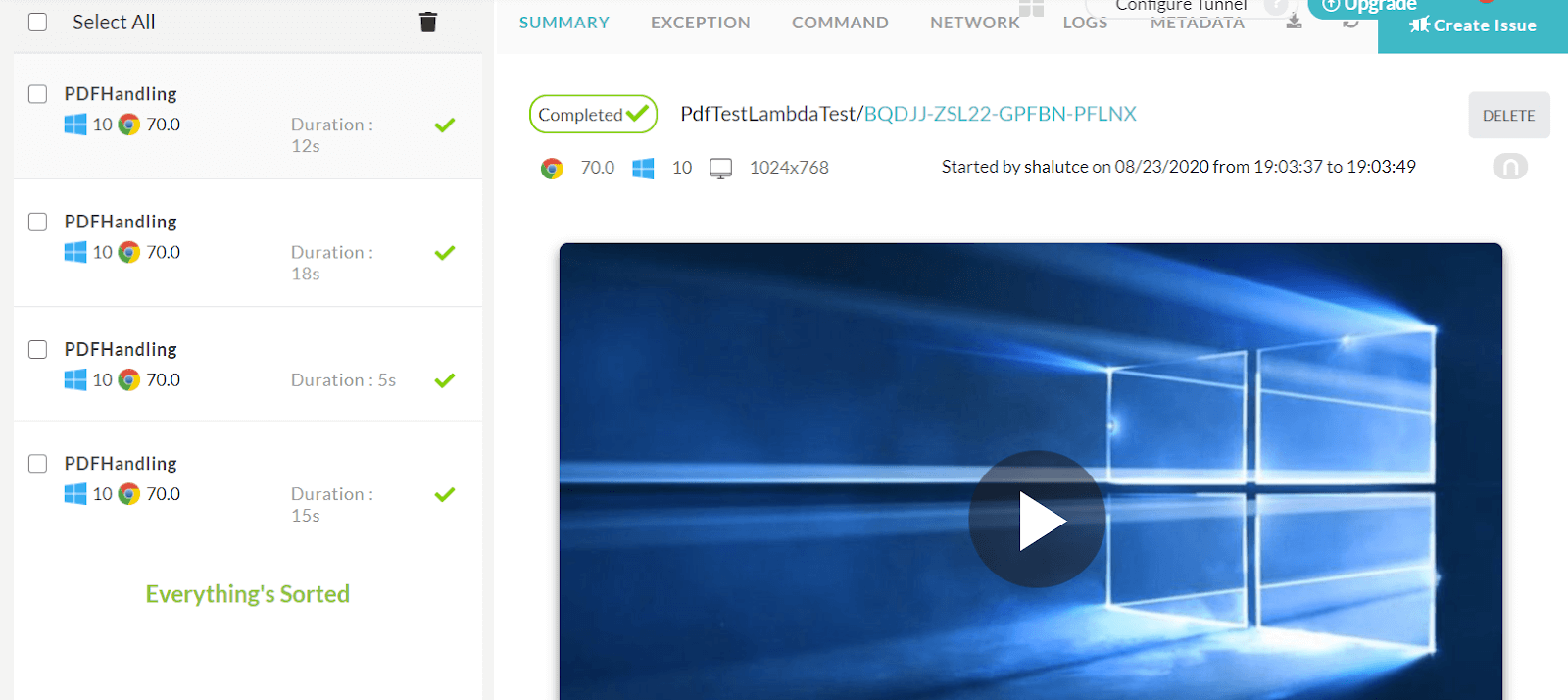 到目前为止,我已经解释了使用硒进行PDF测试的必要性。 这篇有关Selenium测试PDF文件的帖子解释了有关使用Apache PDFBox,PDFTextStripper和TestNG断言的所有内容。 从特定页面提取内容到验证其内容,您可以在LambdaTest中执行所有这些操作。
到目前为止,我已经解释了使用硒进行PDF测试的必要性。 这篇有关Selenium测试PDF文件的帖子解释了有关使用Apache PDFBox,PDFTextStripper和TestNG断言的所有内容。 从特定页面提取内容到验证其内容,您可以在LambdaTest中执行所有这些操作。
在Selenium测试自动化中处理PDF并进行验证可能非常棘手。 希望大家都对Selenium测试PDF文件有所了解。 如果您在处理PDF文件时遇到任何其他挑战,请在下面分享您的经验。 我们希望收到有关硒测试PDF文件的反馈。 请与您的同事和同事分享这篇文章,因为这可能对他们有所帮助。 敬请期待,直到快乐测试.. !!!
author
石头 磊哥 seven 随便叫
company
thoughtworks
大家好,本人不才,目前依旧混迹于thoughtworks,做着一名看起来像全栈的QA,兴趣爱好前端,目前是thoughtworks 西安QA社区的leader,如果有兴趣分享话题,或者想加入tw,可以找我
roles
QA(营生) dev(front-end dev 兴趣爱好)
联系方式
如果想转载或者高薪挖我 请直接联系我 哈哈
wechat:
qileiwangnan
email:
qileilove@gmail.com
